
关于杠r的那些事
这是我在大一一位C语言助教的作品,因为非常喜欢,本文经过原作者同意将其搬运到了我的博客当中(有所删改)。如果对本内容有相关疑问,欢迎联系1706zcy@buaa.edu.cn。
开头语
这是一个十分令人头疼的问题,头疼你我他,即便是老师和助教,一个不小心也不可避免地会犯下这样的错误。
同学们在做题的时候,一般在Windows 系统下本地测试,助教们也普遍在Windows 系统下进行数据的生成。虽然OJ一般来说会自动去掉行末的空白字符再进行评测,但是有的时候也同样会出现问题。
然后导致的问题就是,同学们要无缘无故地为这样的错误买单,部分的助教和老师们也会认为这是一个大家本就该考虑到的问题。这也会导致双方无法在这个问题上达成共识,在很多题目上助教和老师一个给不出解决的方法。在北航,每一年都要因为这个事情闹一次争执一次,一直得不到有效的解决方法,故笔者打算写一篇说明,针对这个问题进行一下科普。
关于\r和\n的来历
以下内容摘自该博客 : https://www.cnblogs.com/the-tops/p/5626828.html。
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的玩意,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。
于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做回车,告诉打字机把打印头定位在左边界;另一个叫做换行,告诉打字机把纸向下移一行。
这就是换行和回车的来历,从它们的英语名字上也可以看出一二。
后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧。
Unix系统里,每行结尾只有<换行>,即\n;Windows系统里面,每行结尾是<换行><回车>,即\r\n;Mac系统里,每行结尾是<回车>。一个直接后果是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
c语言编程时(windows系统)\r就是return 回到 本行 行首 这就会把这一行以前的输出 覆盖掉。
以下内容摘自该博客 : https://blog.csdn.net/lgouc/article/details/7815523。
记得在Windows下学X86汇编语言时,用0DH(
\r)和0AH(\n)来输出回车(跳到下一行的开始处)。问题来了,在Windows下是先回车再换行呢还是先换行再回车呢?在Unix系统下换行只有\n,MACOS下只有\r(网上是这么说的, 没用过Mac OS, 无从证实),都不会出现上述的问题。
现在新建一个文本文档,其内容如下:
现在用C语言二进制形式将其读入字符串并按十进制输出。结果如下:
可以看出回车是 13 和 10 也就是
\r和\n,即先回车后换行。


一言以蔽之,有如下的区别。
- 回车符
\r和换行符\n,是 2 个符。一个回车,一个换行。\r仅仅是回车,\n是换行。一个是控制
屏幕或者从键盘的Enter键输入。另一个是控制“打印机”! - 回车 = 光标到达最左侧,换行 = 移到下一行。如果只回车,打印的东西会覆盖同行以前的内容,如
果只换行,打印的东西会在下一行的先一个位置继续。 \r实际是回到行首。\n如果下一行已经有了一些内容的话它会在那些内容的后边.因为一般
情况下下一行是没有数据的,很多时候\n也就成了\r\n作用一样。
在Linux系统下\r的具体表现形式
输出\r
我们用不同的程序来演示一下
1 | |

可以看到其输出为
1 | |
输入\r
以下面的样例为例
1 | |
可以看到,这两行的长度是完全一致的,且行末都没有空格。
但是如果该数据是在Windows 系统下,写程序,通过文件重定向生成的,以最后一行作为文件的结尾,我们采用以下程序来查看每一个字符串的长度。
1 | |
以下Windows 10 系统下的devcpp 查看到的输出:
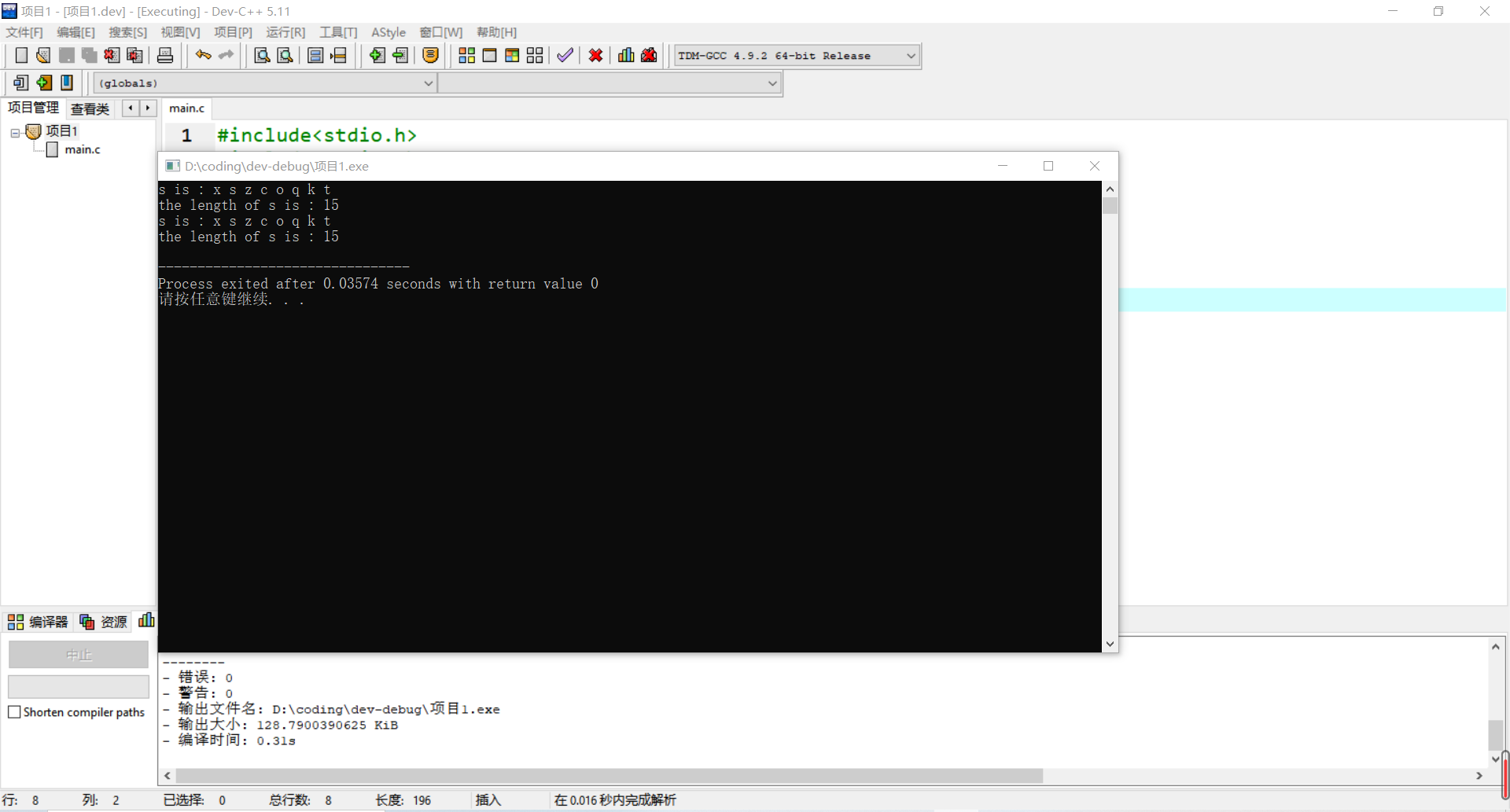
1 | |
而在以Linux 环境下部署的在线IDE当中所看到的输出却是这样的:
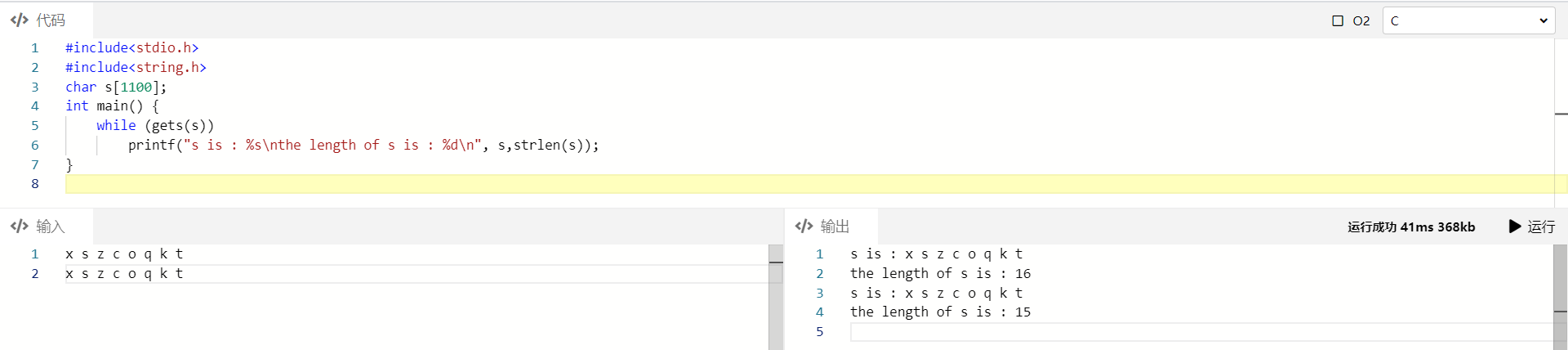
1 | |
看到差别了吗?第一行和第二行的长度,在Linux 下竟然是不同的!
说白了,这就是第一行的\r 在作祟(而第二行的末尾没有换行,直接就是EOF了, EOF也不会计算在字符串内)
对同学们来说的解决办法
作为同学,日后如果依旧要写代码,无论是做什么工作,都会不可避免地和\r 打交道。为此,也就有必要了解处理\r 的办法。
一般来说,直接使用scanf函数的话,除了采用%c读取单个字符之外,都会直接略过所有的空白字符(显然, \r也在此列),基本不需要处理这样的问题。
但是如果采用gets或者fgets函数,则需要考虑行末\r的问题。
而鉴于gets函数已经在现有的C/C++标准当中被废除(只有devcpp等老旧的IDE才可以使用),所以推荐大家在日后写代码的时候,采用fgets函数。
采用fgets函数的解决方法
1 | |
采用fgets函数的解决方法
1 | |
C++语言采用getline函数的解决方法
1 | |
节后语
没什么想说的,只希望这篇文章能够帮助大家,让同学们少一些疑惑,减少老师、助教与学生之间在这个问题上年复一年的纷争。
——开花学长